먼저 이진트리는 각각의 노드가 최대 두 개의 자식 노드를 가지는 트리 자료구조다.
이진트리의 종류로
정이진트리 : 트리의 모든 node가 0개 혹은 2개의 자식을 갖는 트리
포화이진트리 : leaf node가 끝까지 꽉 찬 트리
완전이진트리 : 마지막 레벨을 제외한 모든 레벨에서 순서대로 node가 채워진 트리
균형이진트리 : leaf node들의 레벨 차이가 최대 1레벨까지만 나는 트리
등이 있는데 오늘 얘기할 B-Tree는 균형이진트리에 속한다.
균형이진트리는 한 쪽으로 데이터가 쏠릴 수 있는 현실에서도 트리의 높이를 균형적으로 유지시켜줄 수 있어
많이 사용되는 자료구조이며, 검색할 때 최악의 시간복잡도가 O(log N)으로 굉장히 안정적이다.
B-Tree
B-Tree는 Balanced-tree로 이진트리와 다르게 하나의 노드가 두 개 이상의 자식을 가질 수도 있는 트리 구조이다.
B트리에는 차수라는 개념이 있는데
최대 M개의 자식을 가질 수 있는 B-Tree를 M차 B-Tree라고 부른다.
하나의 노드에 여러 자료를 배치하면서 이진 트리보다 훨씬 많은 데이터를 더 효율적으로 저장소에 담을 수 있게 되었다. 하나의 노드에 하나의 데이터를 저장하는 것보다 Tree의 키, 즉 height을 줄여 탐색 시간을 줄였다.
디스크나 SSD 같은 외부 기억장치는 파일을 블럭 단위로 입출력하는데,
이때 발생하는 입출력의 비용은 파일의 크기와 상관없이 동일하다!
그래서 하나의 블럭에 여러 데이터들을 동시에 저장해 블럭을 보다 효율적으로 사용할 수 있다.
이 이유로 많은 데이터베이스에서 B-Tree를 사용한다.
먼저 특징을 알아보자.
B-Tree의 특징
- 각 노드의 자료는 정렬되어 있다.
- 자료는 중복되지 않는다.
- 모든 leaf node는 같은 레벨에 있다.
- root node는 자신이 leaf node가 되지 않는 이상 적어도 2개 이상의 자식을 가진다.
- root node와 leaf node를 제외한 노드들은 최대 M개부터 최소 M/2개까지의 자식을 가질 수 있다.
(4차 B트리에서 최소 2개~최대 4개의 자식을 가진다) - 각 노드에는 최소 M/2 - 1개 ~ 최대 M-1개의 키가 포함될 수 있다.
(4차 B트리에서 각 노드는 최소 1개~최대 3개의 키를 포함한다) - 노드의 키가 x개일 때 자식의 수는 x+1개이다.
- 최소차수는 키의 개수의 하한값을 의미하며, 모든 노드는 2t-1개 이하의 키를 가진다.
따라서 하나의 내부 노드는 자식 노드를 최대 2t개 가진다.
아래 그림은 https://www.cs.usfca.edu/~galles/visualization/BTree.html에서 만들어본 트리다. 여러 사이트에서 B트리에 대해 알아보는데 데이터, 노드, 키, 자식 같은 단어들이 각각 무엇을 뜻하는지 너무 헷갈려서 정리해보려고 만들었다.
B-Tree Visualization
www.cs.usfca.edu
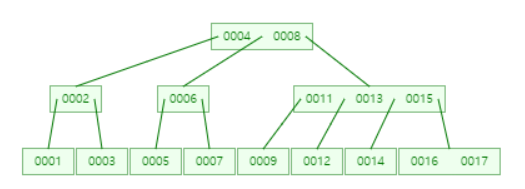
그림에서 root 노드는 4와 8이라는 키를 가진다.
11, 13, 15의 키를 가진 노드는 4개의 자식을 갖고 있다. 최대 키값에 최대 자식을 가진 노드이다.
키 2와 6을 가진 노드는 키값을 최소로, 자식을 최소로 갖고 있는 노드이다.
B*Tree
B-Tree의 단점 중 하나는 구조를 유지하기 위해 추가적인 연산이 수행되거나 새로운 노드가 생성된다는 것.
추가 연산을 최소화하기 위해 B-Tree에서 규칙이 추가된 것이 B*Tree다.
가장 대표적인 차이점은 최소 M/2개의 키값을 가져야 했던
자식 노드 수 최소 제약 조건이 2M/3개로 늘어났고, 노드가 가득 차면 분열하는 대신 이웃한 형제 노드로 재배치를 한다. (더이상 재배치를 할 수 없는 시점에 분열)
- root node가 아닌 노드들은 적어도 2[(M-2)-3]+1개의 자식 노드를 가진다. (최대 M개)
B+Tree
B-Tree는 탐색을 위해서 노드를 찾아 이동해야 한다는 단점을 갖고 있다.
이런 단점을 해소하기 위해 B+Tree는 같은 레벨의 모든 키값들이 정렬되어 있고,
같은 레벨의 형제 node는 연결리스트 형태로 이어져 있다.
특정 데이터를 찾아야 하는 상황에서 leaf node에 모든 데이터가 존재하고, 그 데이터들이 연결리스트로 연결되어 있기 때문에 탐색에 있어서 굉장히 유리하다.
leaf node가 아닌 자료는 인덱스 노드라고 하고, leaf node는 데이터 노드라고 부른다.
인덱스 노드의 Value값에는 다음 노드를 가리키는 포인터 주소가,
데이터 노드의 Value값에는 데이터가 존재한다.
따라서 키값은 중복(!!)될 수 있고, 데이터 검색을 위해서는 반드시 leaf node까지 내려가야 한다는 특징이 있다.
뭔가 제대로 이해는 안 됐는데 올려본다...나중에 수정해야지
출처:
https://ssocoit.tistory.com/217
[자료구조] 간단히 알아보는 B-Tree, B+Tree, B*Tree
위 글을 보고 정리를 하지 않을 수 없었습니다. 가슴이 시키네요;; 그렇다면 바로 B-Tree, B*Tree, B+Tree의 특징에 대해서 알아봅시다. 목차 0. 이진트리 B-Tree, B*Tree, B+Tree에 대해서 알아보자면서 갑자
ssocoit.tistory.com
https://yeongjaekong.tistory.com/38
[자료구조] B-tree란? / B-tree의 연산 / B*tree, B+tree / B+tree 구현
B-tree란? B-tree는 Self-balanced Tree 중 가장 유명한 자료구조입니다. Balanced-tree를 의미하며, 이진트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조입니다. 즉,
yeongjaekong.tistory.com
'알고리즘' 카테고리의 다른 글
| LCS (Longest Common Subsequence) (2) | 2024.01.25 |
|---|---|
| 최소 신장 트리란? (0) | 2024.01.21 |
| 이진 탐색 알고리즘 (0) | 2024.01.19 |
| 그래프(Graph)란? (0) | 2024.01.18 |
| 피보나치 수열(반복문, 재귀함수) (0) | 2024.01.16 |
